راهنمای جامع بهینهسازی علمی استراتژیهای معاملاتی بوسیله ی پایتون : از جستجوی ساده پارامترها تا جلوگیری از اورفیتینگ با اعتبارسنجی پیشرفته و تحلیل Heatmap
در مقاله قبلی، “چگونه یک استراتژی ساده را به کمک پایتون بکتستگیری کنیم؟“، استراتژی SMA Crossover را پیادهسازی کردیم و حتی با افزودن RSI و حد سود/ضرر آن را ارتقا دادیم. اما یک سوال حیاتی باقی میماند: آیا پارامترهای ۲۰ و ۵۰ برای SMA بهترین انتخاب بودند؟ چرا ۱۸ و ۴۵ نباشد؟ یا ۲۲ و ۶۰؟
پاسخ دادن به این سوالات با روش آزمون و خطای دستی کار زمان بری است. اینجاست که بهینهسازی خودکار (Automated Optimization) وارد میشود. در این مقاله، با استفاده از Python و کتابخانه backtesting.py، یاد میگیریم چگونه بهترین پارامترها را برای استراتژی خود به صورت علمی و سیستماتیک پیدا کنیم.
ما در این مسیر، بهینهسازی را از ساده تا پیچیده پیش میبریم:
در پایان، شما قادر خواهید بود هر استراتژی را بهینه کرده و با اطمینان بیشتری در بازار واقعی به کار بگیرید.
اورفیتینگ (Overfitting) بزرگترین دام در بهینهسازی است. اورفیتینگ زمانی اتفاق میافتد که استراتژی آنقدر به دادههای تاریخی خاص تنظیم میشود که فقط بر روی آن دادهها عالی کار میکند و در مواجهه با دادههای جدید (آینده) شکست میخورد.
هدف ما بهینهسازی هوشمندانه است، نه اورفیت کردن! در طول این مقاله، تکنیکهای متعددی برای کاهش این خطر یاد خواهیم گرفت.
بهینهسازی در اصل یک مسئله جستجو است. ما باید در میان هزاران ترکیب ممکن پارامترها، ترکیبی را بیابیم که منجر به بهترین عملکرد شود.
ابتدا استراتژی پایه مقاله قبل (با SL/TP) را بارگذاری و دادههای جدیدی دانلود میکنیم.
import pandas as pd
import numpy as np
import yfinance as yf
from backtesting import Backtest, Strategy
from backtesting.lib import crossover
import warnings
warnings.filterwarnings('ignore')
# --- تعریف استراتژی پایه SMA با SL/TP (از مقاله قبل) ---
class SMACrossWithSLTP(Strategy):
"""استراتژی SMA Crossover همراه با حد سود و ضرر."""
n1 = 20 # SMA کوتاه (پارامتر بهینهسازی)
n2 = 50 # SMA بلند (پارامتر بهینهسازی)
tp = 0.15 # حد سود 15% (پارامتر بهینهسازی)
sl = 0.05 # حد ضرر 5% (پارامتر بهینهسازی)
def init(self):
close = self.data.Close
self.sma1 = self.I(lambda x: pd.Series(x).rolling(self.n1).mean(), close)
self.sma2 = self.I(lambda x: pd.Series(x).rolling(self.n2).mean(), close)
def next(self):
price = self.data.Close[-1]
if not self.position and crossover(self.sma1, self.sma2):
self.buy(sl=price * (1 - self.sl), tp=price * (1 + self.tp))
elif self.position and crossover(self.sma2, self.sma1):
self.position.close()
# --- دانلود و تقسیم داده ---
print("📥 آمادهسازی دادهها برای بهینهسازی...")
filename = 'BTCUSDT-1d.csv'
full_data = pd.read_csv(filename, parse_dates=True, index_col='timestamp')
# مطمئن شوید داده ها همه ستونهای مورد نیاز برای محاسبات بکتست گیری و بهینه سازی را دارند
# در صورتیکه فایل داده ها ستونهای دیگری داشت، نام آنها را بروزرسانی کنید
full_data.rename(columns={
'open': 'Open',
'high': 'High',
'low': 'Low',
'close': 'Close',
'volume': 'Volume'
}, inplace=True)
# تقسیم به دو بخش: آموزش (In-Sample) و تست (Out-of-Sample)
# 70% اول برای آموزش و بهینهسازی
# 30% آخر برای اعتبارسنجی نهایی
split_ratio = 0.7
split_index = int(len(full_data) * split_ratio)
train_data = full_data.iloc[:split_index] # داده آموزش
test_data = full_data.iloc[split_index:] # داده تست (برای مرحله آخر)
print(f"📊 کل دادهها: {len(full_data)} روز")
print(f"📚 داده آموزش (برای بهینهسازی): {len(train_data)} روز ({split_ratio*100:.0f}%)")
print(f"🧪 داده تست (برای اعتبارسنجی): {len(test_data)} روز ({(1-split_ratio)*100:.0f}%)")
print(f"📅 آموزش: {train_data.index[0].date()} تا {train_data.index[-1].date()}")
print(f"📅 تست: {test_data.index[0].date()} تا {test_data.index[-1].date()}")
با اجرای کد بالا، داده های تاریخی از یک فایل CSV خوانده میشوند و سپس به دو بخش آموزش و تست تقسیم میشوند. با اجرای این کُد، شما خروجی زیر را در ترمینال مشاهده خواهید کرد:

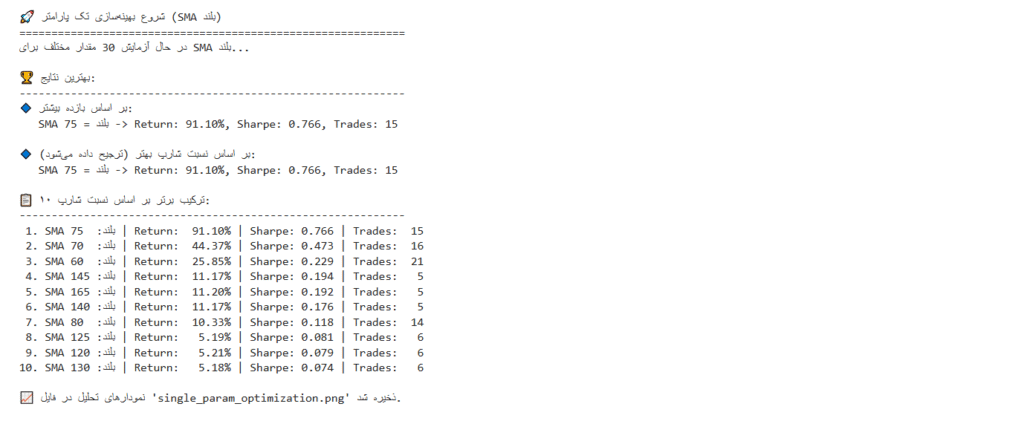
بیایید ساده شروع کنیم. فرض میکنیم SMA کوتاه را روی ۵۰ روز ثابت نگه داشتهایم و میخواهیم بهترین مقدار برای SMA بلند (n2) را پیدا کنیم که بیشترین بازده (Return) را ایجاد میکند.
ما یک حلقه میزنیم و استراتژی را با مقادیر مختلف n2 (مثلاً از ۵۵ تا ۲۰۰) اجرا میکنیم. سپس خروجی هر اجرا را ذخیره و در پایان، مقداری که بالاترین بازده را داشته، انتخاب میکنیم.
تابع هدف: ماکزیمم کردن بازدهی کل
فضای جستجو: n2 = [۵۵, ۶۰, ۶۵, …, ۱۹۵, ۲۰۰]
print("\n🚀 شروع بهینهسازی تک پارامتر (SMA بلند)")
print("="*60)
# تعریف محدوده مقادیر برای SMA بلند
n2_values = range(55, 205, 5) # از 55 تا 200 با گام 5
print(f"در حال آزمایش {len(n2_values)} مقدار مختلف برای SMA بلند...")
results = []
for n2 in n2_values:
# ایجاد یک کلاس استراتژی موقت با پارامتر n2 جاری
class TempStrategy(SMACrossWithSLTP):
n1 = 50 # ثابت
n2 = n2 # متغیر
sl = 0.05 # ثابت
tp = 0.15 # ثابت
# اجرای بکتست با پارامترهای جاری
bt = Backtest(train_data, TempStrategy,
cash=10000000,
commission=.002,
exclusive_orders=True)
output = bt.run()
# ذخیره نتایج
results.append({
'n2': n2,
'Return': output['Return [%]'],
'Sharpe': output.get('Sharpe Ratio', 0),
'Trades': output['# Trades'],
'WinRate': output['Win Rate [%]'],
'MaxDD': output['Max. Drawdown [%]']
})
# تبدیل نتایج به DataFrame برای تحلیل آسانتر
results_df = pd.DataFrame(results)
# یافتن بهترین نتیجه بر اساس Return
best_by_return = results_df.loc[results_df['Return'].idxmax()]
# یافتن بهترین نتیجه بر اساس Sharpe Ratio (معیار بهتر)
best_by_sharpe = results_df.loc[results_df['Sharpe'].idxmax()]
# نمایش نتایج
print("\n🏆 بهترین نتایج:")
print("-"*60)
print(f"🔹 بر اساس بازده بیشتر:")
print(f" SMA بلند = {int(best_by_return['n2'])} -> Return: {best_by_return['Return']:.2f}%, Sharpe: {best_by_return['Sharpe']:.3f}, Trades: {int(best_by_return['Trades'])}")
print(f"\n🔹 بر اساس نسبت شارپ بهتر (ترجیح داده میشود):")
print(f" SMA بلند = {int(best_by_sharpe['n2'])} -> Return: {best_by_sharpe['Return']:.2f}%, Sharpe: {best_by_sharpe['Sharpe']:.3f}, Trades: {int(best_by_sharpe['Trades'])}")
# نمایش ۱۰ ترکیب برتر
print("\n📋 ۱۰ ترکیب برتر بر اساس نسبت شارپ:")
print("-"*60)
top_10 = results_df.sort_values(by='Sharpe', ascending=False).head(10)
for i, (_, row) in enumerate(top_10.iterrows(), 1):
print(f"{i:2d}. SMA بلند={int(row['n2']):3d} | Return: {row['Return']:6.2f}% | Sharpe: {row['Sharpe']:5.3f} | Trades: {int(row['Trades']):3d}")
# رسم نمودار رابطه SMA بلند با بازده و نسبت شارپ
import matplotlib.pyplot as plt
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 8))
# نمودار بازده
ax1.plot(results_df['n2'], results_df['Return'], 'b-', linewidth=1.5, alpha=0.7, label='Return %')
ax1.axvline(x=best_by_return['n2'], color='r', linestyle='--', alpha=0.7, label=f'Optimized (Return) = {best_by_return["n2"]}')
ax1.set_xlabel('Long SMA period (n2)')
ax1.set_ylabel('Return %')
ax1.set_title('Long SMA period relation with strategy return')
ax1.grid(True, alpha=0.3)
ax1.legend()
# نمودار نسبت شارپ
ax2.plot(results_df['n2'], results_df['Sharpe'], 'g-', linewidth=1.5, alpha=0.7, label='Sharpe ratio')
ax2.axvline(x=best_by_sharpe['n2'], color='orange', linestyle='--', alpha=0.7, label=f'Optimized (Sharpe Ratio) = {best_by_sharpe["n2"]}')
ax2.set_xlabel('Long SMA period (n2)')
ax2.set_ylabel('Sharpe Ratio')
ax2.set_title('Long SMA period relation with Sharpe ratio')
ax2.grid(True, alpha=0.3)
ax2.legend()
plt.tight_layout()
plt.savefig('single_param_optimization.png', dpi=150, bbox_inches='tight')
print(f"\n📈 نمودارهای تحلیل در فایل 'single_param_optimization.png' ذخیره شد.")
plt.show()
با اجرای کد بالا خروجی زیر در ترمینال نمایش داده میشود:
همچنین نمودارهای زیر در ترمینال یا در صفحه وب (بسته به محیط اجرای کد که محیط نوت بوک یا ادیتور کد باشد) به نمایش در میآیند:
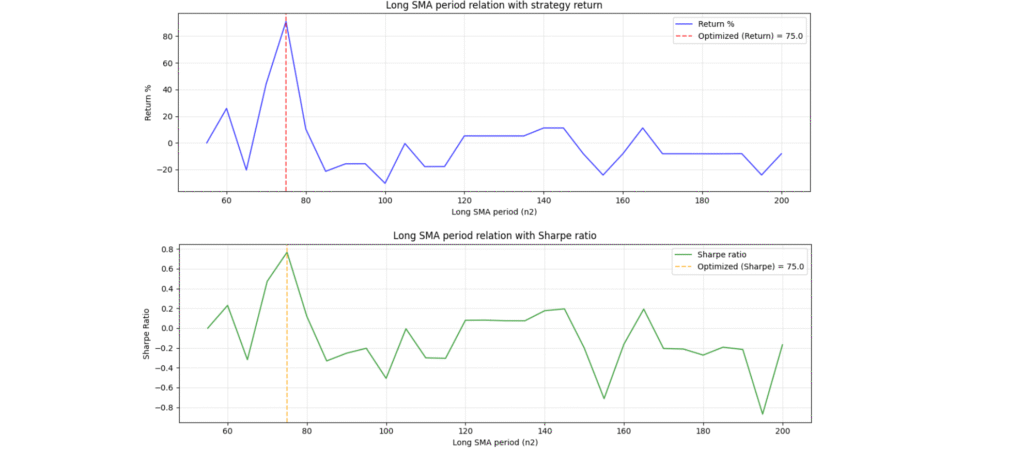
پس از اجرای کد بالا، به چند نکته مهم پی میبریم:
در دنیای واقعی، ما فقط یک پارامتر را تغییر نمیدهیم. باید بهترین ترکیب پارامترها را پیدا کنیم. همچنین نیاز داریم تابع هدف پیچیدهتری تعریف کنیم که چندین فاکتور را همزمان در نظر بگیرد.
تابع هدف زیر را در نظر بگیرید که میخواهیم آن را ماکزیمم کنیم:
Score = (Return %) × (تعداد معاملات) × (نشانگر پایداری)
که در آن:
print("\n🚀 شروع بهینهسازی دوپارامتر با تابع هدف سفارشی")
print("="*70)
def custom_objective_function(output):
"""
تابع هدف سفارشی برای بهینهسازی.
ترکیبی از بازده، تعداد معاملات و کنترل ریسک.
"""
return_pct = output['Return [%]']
num_trades = output['# Trades']
max_dd = output['Max. Drawdown [%]']
sharpe = output.get('Sharpe Ratio', 0)
# 1. جریمه برای تعداد معاملات کم (کمتر از 5 معامله غیرقابل اعتماد است)
if num_trades < 5:
trade_penalty = 0.1 # جریمه 90%
elif num_trades < 10:
trade_penalty = 0.5 # جریمه 50%
else:
trade_penalty = 1.0 # بدون جریمه
# 2. جریمه برای افت سرمایه زیاد
if max_dd > 30:
dd_penalty = 0.1 # افت بیشتر از 30%: جریمه 90%
elif max_dd > 20:
dd_penalty = 0.5 # افت بین 20-30%: جریمه 50%
else:
dd_penalty = 1.0 # افت کمتر از 20%: بدون جریمه
# 3. پاداش برای نسبت شارپ خوب
if sharpe > 1.5:
sharpe_bonus = 1.5
elif sharpe > 1.0:
sharpe_bonus = 1.2
else:
sharpe_bonus = 1.0
# محاسبه نمره نهایی
# میتوانیم از ترکیب ضربی یا جمعی استفاده کنیم
score = return_pct * trade_penalty * dd_penalty * sharpe_bonus
return score
# محدوده پارامترها برای جستجو
n1_range = range(10, 41, 5) # SMA کوتاه: 10, 15, 20, 25, 30, 35, 40
n2_range = range(50, 121, 10) # SMA بلند: 50, 60, 70, 80, 90, 100, 110, 120
print(f"در حال آزمایش {len(n1_range)} × {len(n2_range)} = {len(n1_range)*len(n2_range)} ترکیب پارامتر...")
multi_results = []
for n1 in n1_range:
for n2 in n2_range:
# اعمال قید: SMA بلند باید بزرگتر از SMA کوتاه باشد
if n2 <= n1:
continue
class TempStrategy(SMACrossWithSLTP):
n1 = n1
n2 = n2
sl = 0.05
tp = 0.15
bt = Backtest(train_data, TempStrategy,
cash=10000000,
commission=.002)
output = bt.run()
score = custom_objective_function(output)
multi_results.append({
'n1': n1,
'n2': n2,
'Score': score,
'Return': output['Return [%]'],
'Sharpe': output.get('Sharpe Ratio', 0),
'Trades': output['# Trades'],
'MaxDD': output['Max. Drawdown [%]']
})
multi_df = pd.DataFrame(multi_results)
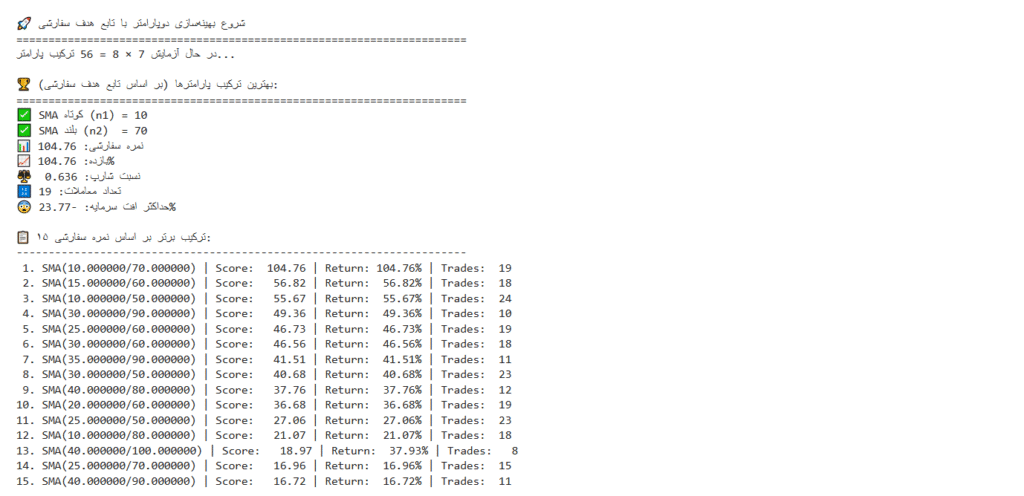
# یافتن بهترین ترکیب بر اساس نمره سفارشی
best_custom = multi_df.loc[multi_df['Score'].idxmax()]
print("\n🏆 بهترین ترکیب پارامترها (بر اساس تابع هدف سفارشی):")
print("="*70)
print(f"✅ SMA کوتاه (n1) = {int(best_custom['n1'])}")
print(f"✅ SMA بلند (n2) = {int(best_custom['n2'])}")
print(f"📊 نمره سفارشی: {best_custom['Score']:.2f}")
print(f"📈 بازده: {best_custom['Return']:.2f}%")
print(f"⚖️ نسبت شارپ: {best_custom['Sharpe']:.3f}")
print(f"🔢 تعداد معاملات: {int(best_custom['Trades'])}")
print(f"😨 حداکثر افت سرمایه: {best_custom['MaxDD']:.2f}%")
# نمایش ۱۵ ترکیب برتر
print("\n📋 ۱۵ ترکیب برتر بر اساس نمره سفارشی:")
print("-"*70)
top_15_custom = multi_df.sort_values(by='Score', ascending=False).head(15)
for i, (_, row) in enumerate(top_15_custom.iterrows(), 1):
print(f"{i:2d}. SMA({row['n1']:3f}/{row['n2']:3f}) | Score: {row['Score']:7.2f} | Return: {row['Return']:6.2f}% | Trades: {int(row['Trades']):3d}")
با اجرای کد بالا خروجی زیر در ترمینال نمایش داده میشود:
کتابخانه backtesting.py دارای یک تابع بهینهسازی داخلی بسیار قدرتمند به نام bt.optimize() است. این تابع نه تنها جستجو را انجام میدهد، بلکه خروجیهای مفیدی مانند Heatmap نیز تولید میکند.
این بار چهار پارامتر (n1, n2, sl, tp) را همزمان بهینه میکنیم و از قیود منطقی استفاده میکنیم.
print("\n🚀 شروع بهینهسازی پیشرفته چهارپارامتر با Heatmap")
print("="*80)
# 1. ایجاد موتور بکتست
bt = Backtest(train_data, SMACrossWithSLTP,
cash=10000000,
commission=.002,
exclusive_orders=True)
# 2. تعریف فضای پارامترها برای بهینهسازی
# میتوان از range، لیست یا tuple استفاده کرد
param_grid = {
'n1': range(10, 35, 5), # 10, 15, 20, 25, 30
'n2': range(40, 110, 10), # 40, 50, 60, 70, 80, 90, 100
'sl': [0.03, 0.05, 0.07, 0.10], # حد ضرر: 3%, 5%, 7%, 10%
'tp': [0.10, 0.15, 0.20, 0.25] # حد سود: 10%, 15%, 20%, 25%
}
# 3. محاسبه تعداد کل ترکیبات
total_combinations = 1
for key in param_grid:
total_combinations *= len(param_grid[key])
print(f"📊 فضای جستجو: {total_combinations} ترکیب پارامتر ممکن")
print("⏳ در حال اجرای بهینهسازی (این مرحله ممکن است چند دقیقه طول بکشد)...")
# 4. اجرای بهینهسازی
# maximize: معیاری که میخواهیم ماکزیمم شود
# constraint: قیدهایی که پارامترها باید رعایت کنند
# return_heatmap: برای تولید Heatmap
# max_tries: محدود کردن تعداد تستها برای سرعت بیشتر (اختیاری)
optimization_stats, heatmap = bt.optimize(
**param_grid,
maximize='Sharpe Ratio', # هدف: ماکزیمم کردن نسبت شارپ
constraint=lambda p: p.n2 > p.n1, # SMA بلند > SMA کوتاه
return_heatmap=True,
max_tries=500, # فقط ۵۰۰ ترکیب را تست کن (برای سرعت)
random_state=42 # برای تکرارپذیری نتایج
)
print("✅ بهینهسازی تکمیل شد!")
# 5. نمایش بهترین پارامترهای یافت شده
print("\n" + "="*80)
print("🎯 بهترین پارامترهای یافت شده:")
print("="*80)
print(f"📊 SMA کوتاه (n1): {optimization_stats['_strategy'].n1}")
print(f"📊 SMA بلند (n2): {optimization_stats['_strategy'].n2}")
print(f"🛑 حد ضرر (SL): {optimization_stats['_strategy'].sl*100:.1f}%")
print(f"🎯 حد سود (TP): {optimization_stats['_strategy'].tp*100:.1f}%")
print(f"\n📈 عملکرد با پارامترهای بهینه:")
print(f" بازده: {optimization_stats['Return [%]']:.2f}%")
print(f" نسبت شارپ: {optimization_stats['Sharpe Ratio']:.3f}")
print(f" حداکثر افت سرمایه: {optimization_stats['Max. Drawdown [%]']:.2f}%")
print(f" تعداد معاملات: {optimization_stats['# Trades']}")
print(f" Win Rate: {optimization_stats['Win Rate [%]']:.1f}%")
# 6. تحلیل Heatmap
print("\n" + "="*80)
print("🔥 تحلیل Heatmap")
print("="*80)
if heatmap is not None and len(heatmap) > 0:
# Convert heatmap to DataFrame if it's a Series
if isinstance(heatmap, pd.Series):
print("⚠️ Heatmap به صورت Series بازگشته است. در حال تبدیل به DataFrame...")
# Convert Series to DataFrame
heatmap_df = heatmap.to_frame('Sharpe Ratio').reset_index()
# Rename columns appropriately
heatmap_df.columns = ['n1', 'n2', 'sl', 'tp', 'Sharpe Ratio']
# For backward compatibility, we'll use this as our main heatmap object
heatmap = heatmap_df
print(f"✅ تبدیل انجام شد. Heatmap شامل {len(heatmap)} ترکیب پارامتر است.")
elif isinstance(heatmap, pd.DataFrame):
print(f"📊 Heatmap شامل {len(heatmap)} ترکیب پارامتر تست شده است.")
else:
print(f"❌ نوع داده Heatmap نامشخص است: {type(heatmap)}")
heatmap = pd.DataFrame() # Create empty DataFrame to avoid further errors
# Only proceed if we have data
if len(heatmap) > 0:
# مرتب کردن بر اساس نسبت شارپ
# Check if 'Sharpe Ratio' column exists
if 'Sharpe Ratio' in heatmap.columns:
heatmap_sorted = heatmap.sort_values(by='Sharpe Ratio', ascending=False)
else:
# If Sharpe Ratio is in the index or Series values
heatmap_sorted = heatmap.sort_values(ascending=False) if isinstance(heatmap, pd.Series) else heatmap
# نمایش ۱۰ ترکیب برتر از Heatmap
print("\n🏆 ۱۰ ترکیب برتر از Heatmap (بر اساس Sharpe Ratio):")
print("-"*80)
# Display top 10 results
for i in range(min(10, len(heatmap_sorted))):
if isinstance(heatmap_sorted, pd.DataFrame):
row = heatmap_sorted.iloc[i]
# Check if parameters are in columns or index
if 'n1' in heatmap_sorted.columns:
n1 = row['n1']
n2 = row['n2']
sl = row['sl'] if 'sl' in row else row.get('sl', 0)
tp = row['tp'] if 'tp' in row else row.get('tp', 0)
sharpe = row['Sharpe Ratio'] if 'Sharpe Ratio' in row else row[0]
returns = row['Return [%]'] if 'Return [%]' in row else 'N/A'
else:
# Parameters might be in the index
params = row.name
n1, n2, sl, tp = params
sharpe = row['Sharpe Ratio'] if 'Sharpe Ratio' in row else row[0]
returns = row['Return [%]'] if 'Return [%]' in row else 'N/A'
else:
# If it's a Series
params = heatmap_sorted.index[i]
if isinstance(params, tuple) and len(params) >= 4:
n1, n2, sl, tp = params[:4]
else:
n1, n2, sl, tp = i, i, 0, 0
sharpe = heatmap_sorted.iloc[i]
returns = 'N/A'
print(f"{i+1:2d}. SMA({int(n1):2d}/{int(n2):3d}) SL:{float(sl)*100:4.1f}% TP:{float(tp)*100:5.1f}% | Sharpe: {float(sharpe):.3f}")
# محاسبه پراکندگی نتایج (برای تشخیص اورفیتینگ)
try:
if isinstance(heatmap, pd.DataFrame) and 'Sharpe Ratio' in heatmap.columns:
sharpe_values = heatmap['Sharpe Ratio']
sharpe_std = sharpe_values.std()
else:
sharpe_values = heatmap if isinstance(heatmap, pd.Series) else None
sharpe_std = sharpe_values.std() if sharpe_values is not None else 0
print(f"\n📐 پراکندگی نتایج در Heatmap:")
print(f" انحراف معیار Sharpe Ratio: {sharpe_std:.3f}")
# اگر انحراف معیار بسیار بالا باشد، نشانه حساسیت زیاد به پارامترهاست (خطر اورفیتینگ)
if sharpe_std > 0.5:
print(" ⚠️ هشدار: پراکندگی Sharpe بالا است. استراتژی ممکن است به پارامترها بیش از حد حساس باشد.")
else:
print(" ✅ پراکندگی متوسط است. استراتژی از پایداری نسبی برخوردار است.")
except Exception as e:
print(f" ⚠️ خطا در محاسبه پراکندگی: {e}")
# 7. ایجاد Heatmap مصور برای دو پارامتر اصلی (n1, n2)
print("\n🎨 در حال ایجاد Heatmap مصور برای SMA کوتاه و بلند...")
try:
# استخراج نتایج برای n1 و n2 (با میانگینگیری روی sl و tp)
simple_heatmap_data = []
# Extract data based on heatmap type
if isinstance(heatmap, pd.DataFrame):
for idx, row in heatmap.iterrows():
if isinstance(idx, tuple) and len(idx) >= 4:
# Parameters are in the index
n1, n2, sl, tp = idx[:4]
sharpe = row['Sharpe Ratio'] if 'Sharpe Ratio' in row else row[0]
returns = row['Return [%]'] if 'Return [%]' in row else 0
else:
# Parameters are in columns
n1 = row['n1'] if 'n1' in row else 0
n2 = row['n2'] if 'n2' in row else 0
sl = row['sl'] if 'sl' in row else 0
tp = row['tp'] if 'tp' in row else 0
sharpe = row['Sharpe Ratio'] if 'Sharpe Ratio' in row else row[0]
returns = row['Return [%]'] if 'Return [%]' in row else 0
simple_heatmap_data.append({
'n1': n1,
'n2': n2,
'Sharpe': sharpe,
'Return': returns
})
else:
# If heatmap is a Series
for (n1, n2, sl, tp), sharpe in heatmap.items():
simple_heatmap_data.append({
'n1': n1,
'n2': n2,
'Sharpe': sharpe,
'Return': 0 # Return data not available in Series
})
if simple_heatmap_data:
simple_df = pd.DataFrame(simple_heatmap_data)
# محاسبه میانگین برای هر ترکیب n1, n2
pivot_sharpe = simple_df.pivot_table(values='Sharpe', index='n1', columns='n2', aggfunc='mean')
# رسم Heatmap
fig, ax1 = plt.subplots(1, 1, figsize=(10, 8))
# Heatmap برای Sharpe Ratio
im1 = ax1.imshow(pivot_sharpe.values, cmap='RdYlGn', aspect='auto')
ax1.set_xticks(range(len(pivot_sharpe.columns)))
ax1.set_xticklabels([str(int(col)) for col in pivot_sharpe.columns])
ax1.set_yticks(range(len(pivot_sharpe.index)))
ax1.set_yticklabels([str(int(row)) for row in pivot_sharpe.index])
ax1.set_xlabel('Long SMA (n2)')
ax1.set_ylabel('Short SMA (n1)')
ax1.set_title('Heatmap: Sharpe ratio average based on SMA parameters')
plt.colorbar(im1, ax=ax1, label='Sharpe Ratio')
# اضافه کردن اعداد در هر خانه
for i in range(len(pivot_sharpe.index)):
for j in range(len(pivot_sharpe.columns)):
ax1.text(j, i, f"{pivot_sharpe.iloc[i, j]:.2f}",
ha="center", va="center", color="black", fontsize=8)
plt.tight_layout()
plt.savefig('heatmap_analysis.png', dpi=150, bbox_inches='tight')
print(f"📈 Heatmap مصور در فایل 'heatmap_analysis.png' ذخیره شد.")
plt.show()
else:
print("❌ دادهای برای ایجاد Heatmap وجود ندارد.")
except Exception as e:
print(f"❌ خطا در ایجاد Heatmap مصور: {e}")
import traceback
traceback.print_exc()
else:
print("❌ Heatmap تولید نشد یا خالی است.")
با اجرای کد بالا خروجی زیر در ترمینال نمایش داده میشود:
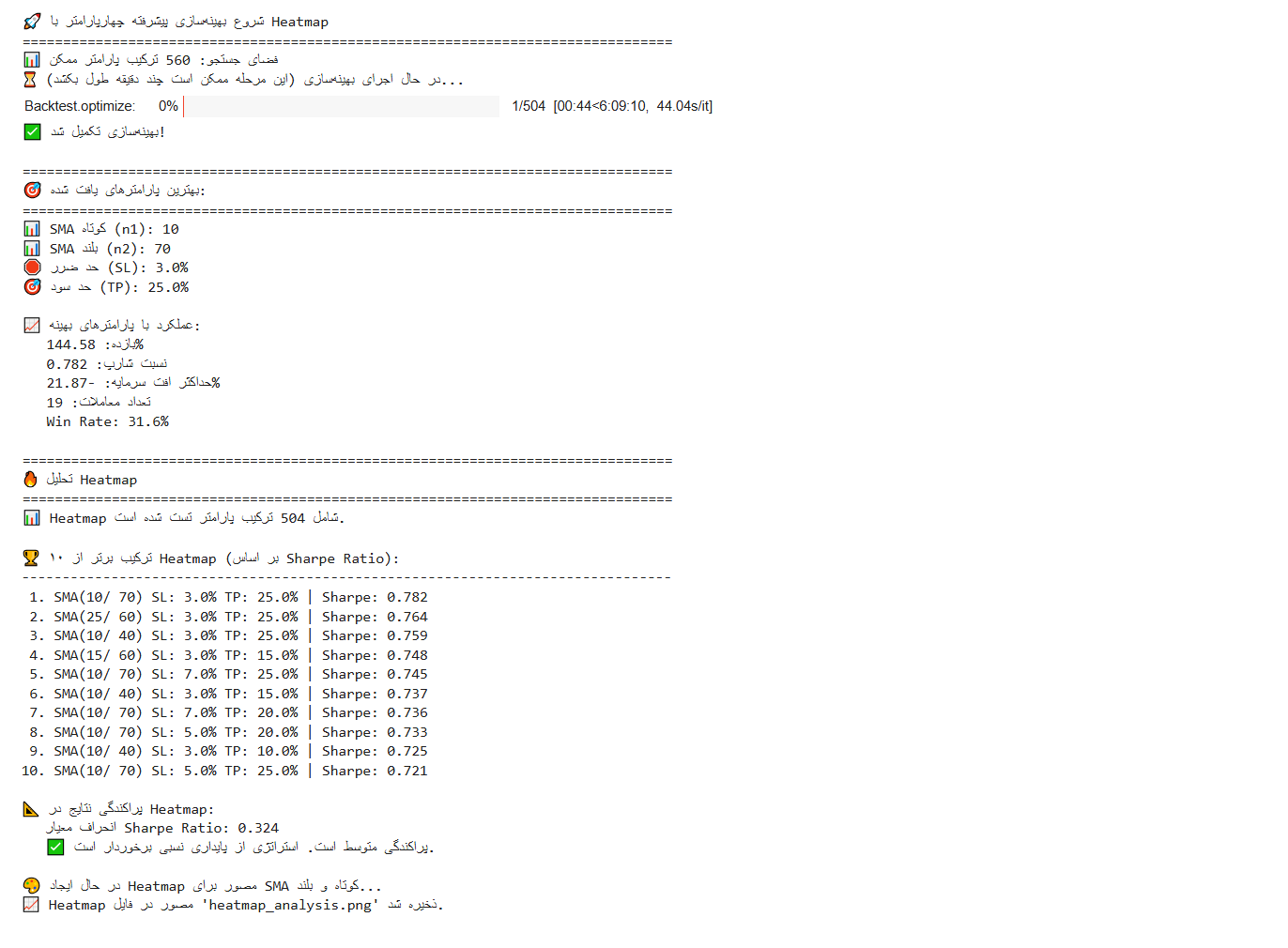
و نقشه گرمایی زیر برای ترکیب پارامترها و مقدار sharpe ratio در خروجی نمایش داده میشود:
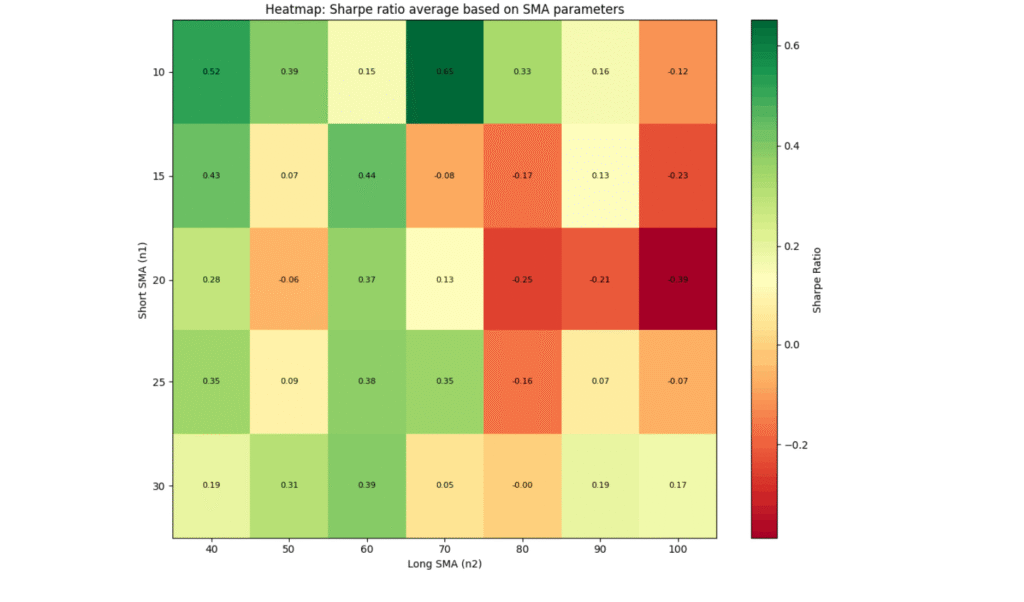
Heatmap یک ابزار تصویری قدرتمند است که میتواند خطرات اورفیتینگ را نشان دهد:
یک استراتژی خوب باید در یک ناحیه از فضای پارامتر خوب عمل کند، نه فقط در یک نقطه خاص.
این مهمترین مرحله است. پارامترهای بهینهشده روی داده آموزش (In-Sample) را روی دادهای که هرگز در فرآیند بهینهسازی استفاده نشده (Out-of-Sample) تست میکنیم.
print("\n🔬 مرحله نهایی: اعتبارسنجی روی داده خارج از نمونه")
print("="*80)
# 1. ایجاد استراتژی با پارامترهای بهینه شده
OptimizedStrategy = type('OptimizedStrategy', (SMACrossWithSLTP,), {
'n1': optimization_stats._strategy.n1,
'n2': optimization_stats._strategy.n2,
'sl': optimization_stats._strategy.sl,
'tp': optimization_stats._strategy.tp
})
# 2. اجرای استراتژی بهینه شده روی داده TEST (خارج از نمونه)
print("🧪 در حال اجرای استراتژی بهینه شده روی داده تست (Out-of-Sample)...")
bt_test = Backtest(test_data, OptimizedStrategy,
cash=10000000,
commission=.002,
exclusive_orders=True)
test_results = bt_test.run()
# 3. اجرای استراتژی با پارامترهای اولیه (بدون بهینهسازی) روی داده TEST
print("🔄 در حال اجرای استراتژی اولیه (پارامترهای دستی) روی داده تست...")
OriginalStrategy = type('OriginalStrategy', (SMACrossWithSLTP,), {
'n1': 20,
'n2': 50,
'sl': 0.05,
'tp': 0.15
})
bt_original = Backtest(test_data, OriginalStrategy,
cash=10000000,
commission=.002,
exclusive_orders=True)
original_results = bt_original.run()
# 4. مقایسه جامع نتایج
print("\n" + "="*80)
print("📊 مقایسه نهایی: عملکرد در داده خارج از نمونه")
print("="*80)
comparison_data = []
metrics_to_compare = ['Return [%]', 'Sharpe Ratio', 'Max. Drawdown [%]',
'# Trades', 'Win Rate [%]', 'Profit Factor']
for metric in metrics_to_compare:
original_val = original_results.get(metric, 0)
optimized_val = test_results.get(metric, 0)
# محاسبه درصد تغییر
if isinstance(original_val, (int, float)) and original_val != 0:
change_pct = ((optimized_val - original_val) / abs(original_val)) * 100
else:
change_pct = 0
comparison_data.append({
'Metric': metric,
'Original': original_val,
'Optimized': optimized_val,
'Change %': change_pct
})
comparison_df = pd.DataFrame(comparison_data)
# نمایش جدول مقایسه
print(f"\n{'Factor':<25} {'Initial':<12} {'Optimized':<12} {'Change %':<10}")
print("-"*60)
for _, row in comparison_df.iterrows():
metric_name = row['Metric']
# فرمتبندی مناسب برای هر معیار
if '%' in metric_name:
original_fmt = f"{row['Original']:.2f}%"
optimized_fmt = f"{row['Optimized']:.2f}%"
elif metric_name == 'Sharpe Ratio' or metric_name == 'Profit Factor':
original_fmt = f"{row['Original']:.3f}"
optimized_fmt = f"{row['Optimized']:.3f}"
else:
original_fmt = f"{row['Original']:.0f}"
optimized_fmt = f"{row['Optimized']:.0f}"
change_fmt = f"{row['Change %']:+.1f}%"
# تعیین رنگ/نماد بر اساس تغییر
if 'Drawdown' in metric_name:
# برای Drawdown، کاهش بهتر است
symbol = "✅" if row['Change %'] < 0 else "⚠️"
else:
# برای سایر معیارها، افزایش بهتر است
symbol = "✅" if row['Change %'] > 0 else "⚠️"
print(f"{symbol} {metric_name:<22} {original_fmt:<12} {optimized_fmt:<12} {change_fmt:<10}")
# 5. محاسبه افت عملکرد (Degradation) - شاخص اصلی اورفیتینگ
# افت عملکرد = (عملکرد در تست) / (عملکرد در آموزش) - 1
train_sharpe = optimization_stats.get('Sharpe Ratio', 0)
test_sharpe = test_results.get('Sharpe Ratio', 0)
train_return = optimization_stats.get('Return [%]', 0)
test_return = test_results.get('Return [%]', 0)
if train_sharpe != 0:
sharpe_degradation = ((test_sharpe - train_sharpe) / abs(train_sharpe)) * 100
else:
sharpe_degradation = 0
if train_return != 0:
return_degradation = ((test_return - train_return) / abs(train_return)) * 100
else:
return_degradation = 0
print("\n" + "="*80)
print("📉 تحلیل افت عملکرد (Degradation Analysis)")
print("="*80)
print(f"Sharpe Ratio در داده آموزش: {train_sharpe:.3f}")
print(f"Sharpe Ratio در داده تست: {test_sharpe:.3f}")
print(f"📊 افت عملکرد Sharpe: {sharpe_degradation:.1f}%")
# 6. نتیجهگیری نهایی درباره اورفیتینگ
print("\n" + "="*80)
print("🎯 نتیجهگیری: آیا استراتژی اورفیت شده است؟")
print("="*80)
if sharpe_degradation > -30 :
print("✅ وضعیت: خوب - افت عملکرد قابل قبول است.")
print(" استراتژی بهینهشده در داده جدید نیز عملکرد نسبتاً خوبی دارد.")
print(" احتمال اورفیتینگ کم است. میتوان با احتیاط در بازار واقعی استفاده کرد.")
elif sharpe_degradation > -50 :
print("⚠️ وضعیت: متوسط - افت عملکرد قابل توجه است.")
print(" استراتژی ممکن است تا حدی اورفیت شده باشد.")
print(" نیاز به بررسی بیشتر و احتمالاً استفاده از پارامترهای محافظهکارانهتر.")
else:
print("❌ وضعیت: ضعیف - افت عملکرد شدید است.")
print(" استراتژی به شدت اورفیت شده است.")
print(" پارامترهای بهینه فقط روی داده آموزش کار میکنند.")
print(" نباید در بازار واقعی استفاده شود.")
# 7. ذخیره تمام نتایج در یک فایل گزارش
import json
report = {
'optimization_parameters': {
'n1': int(optimization_stats._strategy.n1),
'n2': int(optimization_stats._strategy.n2),
'sl': optimization_stats._strategy.sl,
'tp': optimization_stats._strategy.tp
},
'in_sample_performance': {
k: (float(v) if isinstance(v, (int, float)) else v)
for k, v in optimization_stats.items()
if not k.startswith('_')
},
'out_of_sample_performance': {
k: (float(v) if isinstance(v, (int, float)) else v)
for k, v in test_results.items()
if not k.startswith('_')
},
'degradation_analysis': {
'sharpe_degradation_pct': sharpe_degradation,
'return_degradation_pct': return_degradation
},
'data_info': {
'train_period': f"{train_data.index[0].date()} to {train_data.index[-1].date()}",
'test_period': f"{test_data.index[0].date()} to {test_data.index[-1].date()}",
'symbol': "GOOGL"
}
}
from datetime import datetime
report_filename = f"optimization_final_report_{datetime.now().strftime('%Y%m%d_%H%M')}.json"
with open(report_filename, 'w') as f:
json.dump(report, f, indent=4, default=str)
print(f"\n💾 گزارش کامل با تمام جزئیات در فایل JSON '{report_filename}' ذخیره شد.")
print("\n✨ فرآیند بهینهسازی و اعتبارسنجی با موفقیت به پایان رسید!")
با اجرای کد بالا خروجی زیر در ترمینال نمایش داده میشود:

خبر خوب این که ما در تریدبرد همه این ابزارهای حرفهای را در اختیار شما گذاشتهایم:
میتوانید چندین پارامتر را همزمان تست کنید و “منطقه طلایی” را پیدا کنید.
شما با مشاهده تاریخهای در دسترس برای هر نماد، میتوانید بکتست را به دو یا چند قسمت از نظر بازه زمانی تقسیم کنید. یک بازه زمانی را همواره برای تست استراتژی بهینه شده کنار بگذارید.
تمام معیارهای مهم از نسبت شارپ گرفته تا حداکثر افت سرمایه را به طور خودکار محاسبه میکنیم.
میتوانید استراتژی بهینهشده خود را همزمان روی بازارهای مختلف (کریپتو، فارکس، بورس ایران، طلا) تست کنید تا از پایداری آن مطمئن شوید.
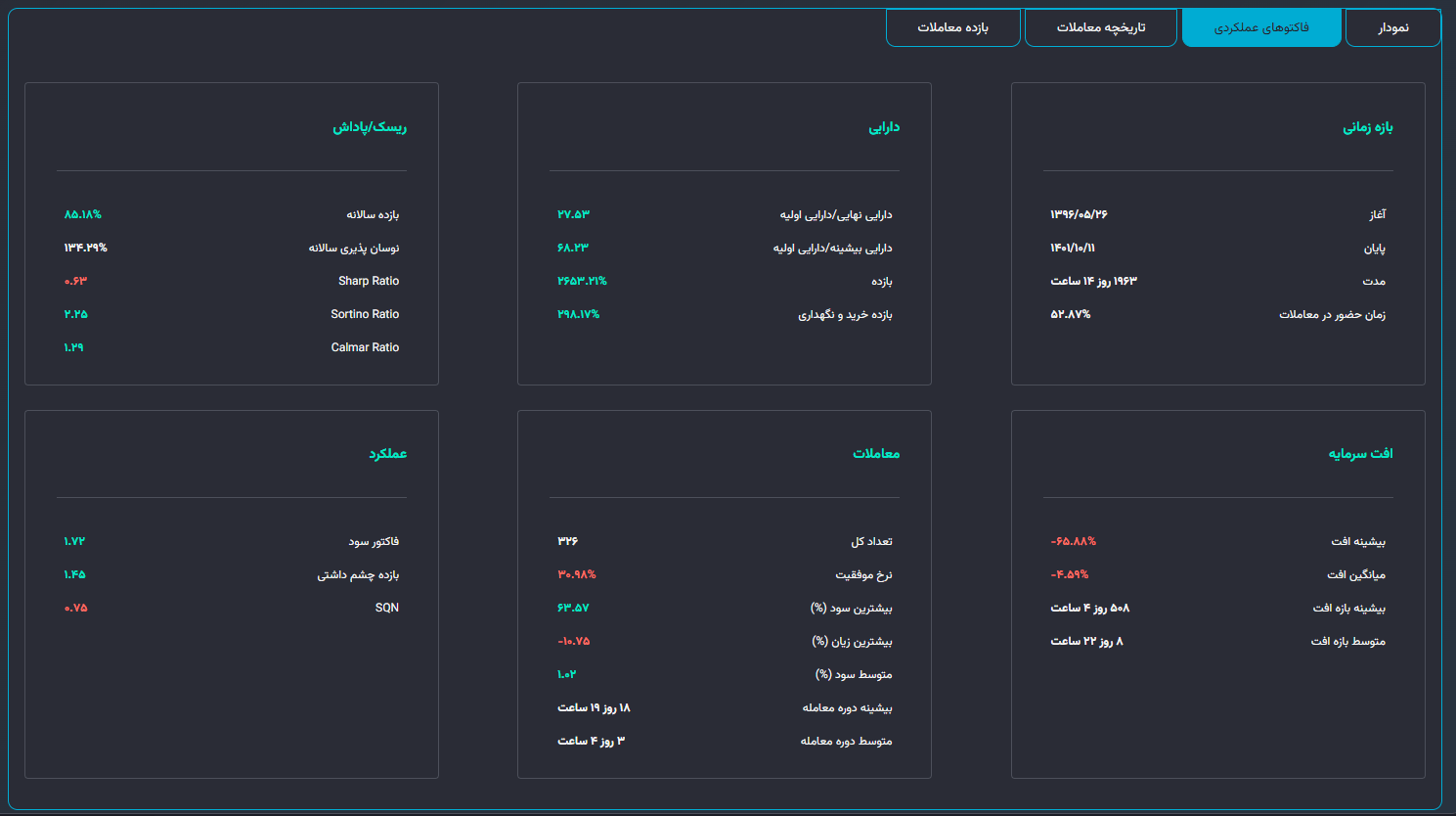
گزارش جامع بکتست گیری در تریدبرد - نمایش معیارهای مختلف آماری
“اگر RSI به زیر ۳۰ برود، بخر.”
تست میکنید و میبینید سطح ۲۵ بهتر از ۳۰ جواب میدهد.
تست میکنید و میبینید “اگر RSI به زیر ۲۵ برود و حجم معاملات ۲۰٪ بالاتر از میانگین ۱۰ روزه باشد” نتیجه بسیار بهتری دارد.
تست روی دادههای خارج از نمونه نشان میدهد این استراتژی بهینهشده نه تنها در دادههای جدید هم جواب میدهد، بلکه در بازارهای مختلف (هم کریپتو و هم طلا) عملکرد پایدار دارد.
کاربران حرفه ای تریدبرد میتوانند درخواست بهینه سازی استراتژی های ساخته شده خود را با مشخص کردن پارامترها و بازه مدنظرشان، بصورت تیکت پشتیبانی در پلتفرم ثبت کنند تا کارشناسان ما در اولین فرصت نتیجه بهینه سازی استراتژی روی پارارمترهای مشخص شده را برای آنها ارسال کنند. این نتیجه بصورت یک گزارش جامع و کامل همراه با نمودارهای گرافیکی خروجی استراتژی به ازای ترکیبات مختلف از پارامترها خواهد بود.
برای آشنایی بیشتر با پلتفرم معاملاتی تریدبرد میتوانید از اینجا فیلم آموزشی تهیه شده را مشاهده نمایید .
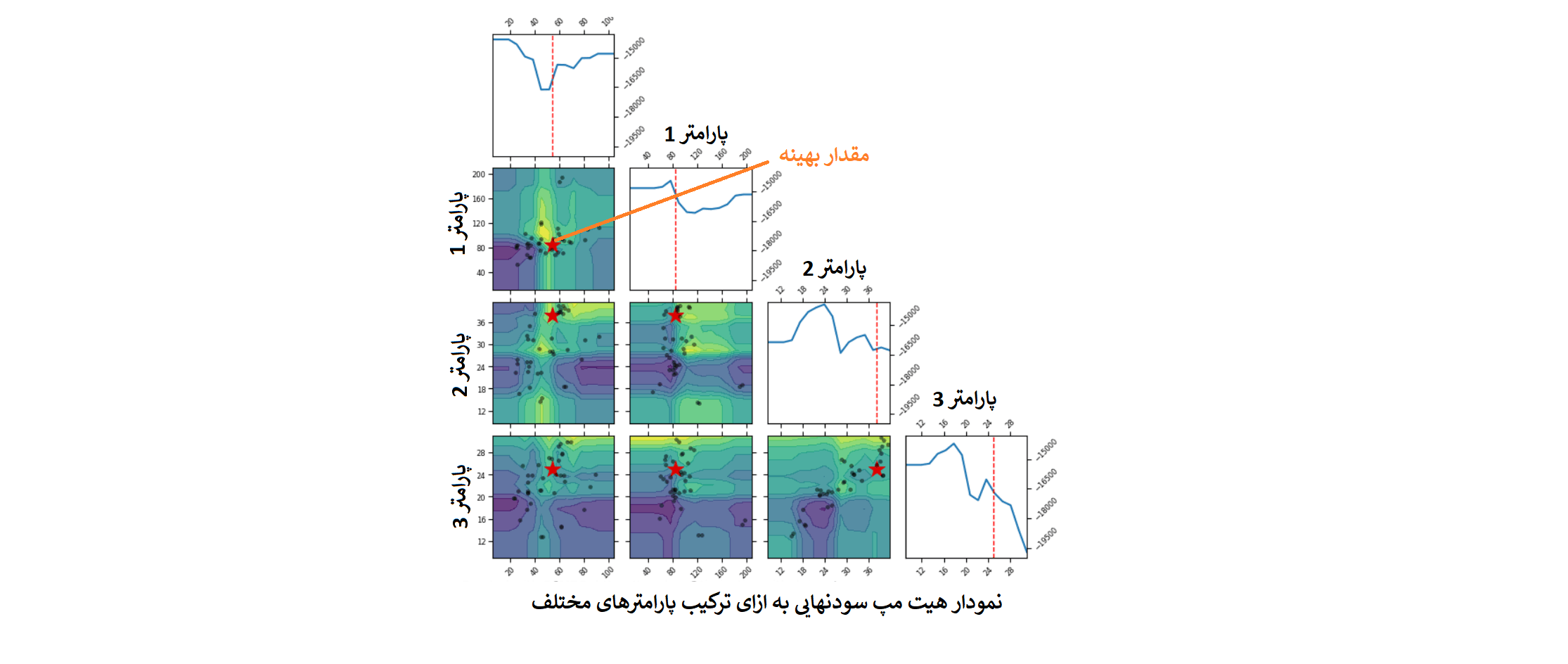
بخشی از گزارش جامع بهسنه سازی در تریدبرد - نمایش سود نهایی استراتژی به ازا یترکیب های مختلف سه پارامتر مختلف
دادهها را به دو بخش آموزش (70-80%) و تست (20-30%) تقسیم کنید. فقط از داده آموزش برای بهینهسازی استفاده کنید.
تابع هدف باید چندبعدی باشد (مثلاً ترکیبی از بازده، ریسک و تعداد معاملات). از ماکزیمم کردن صرف بازده خودداری کنید.
قیودی مثل n2 > n1 یا تعداد معاملات ≥ ۵ اعمال کنید تا جستجو در مسیر منطقی باشد.
Heatmap را بررسی کنید. به دنبال نواحی پایدار باشید، نه نقاط داغ ایزوله.
پارامترهای بهینه را روی داده تست اجرا کنید. افت عملکرد (Degradation) کمتر از ۳۰-۴۰٪ قابل قبول است.
استراتژی بهینه شده را روی چندین سهم مختلف یا بازههای زمانی مختلف تست کنید تا از پایداری آن اطمینان حاصل کنید.
خیر. بهینهسازی فقط بهترین پارامترها را برای داده گذشته پیدا میکند. اگر استراتژی اساساً معیوب باشد یا بازار تغییر کرده باشد، بهینهسازی کمکی نمیکند. بهینهسازی یک ابزار است، نه جادو!
بستگی به استراتژی دارد. برای استراتژیهای کوتاهمدت (اسکالپینگ)بهینهسازی ممکن است ماهانه مورد نیاز باشد، در حالی که استراتژیهای میانمدت تا بلندمدت ممکن است به صورت فصلی یا سالانه اجرا شوند. قاعده کلی: وقتی عملکرد استراتژی به طور مداوم منحرف میشود یا شرایط بازار به شدت تغییر کرده است.
از نظر فنی بله، اما عملاً خطر اورفیتینگ زیاد میشود. بهتر است ابتدا پارامترهای اصلی را بهینه کنید، سپس پارامترهای فرعی. همچنین میتوانید از تکنیکهایی مانند بهینهسازی گام به گام استفاده کنید.
Grid Search: همه ترکیبات ممکن را تست میکند. کامل اما کند.
Random Search: ترکیبات را تصادفی انتخاب میکند. سریعتر و اغلب برای فضای پارامتر بزرگ بهتر است.
کتابخانه backtesting.py از ترکیبی از هر دو استفاده میکند.
بهینهسازی استراتژی معاملاتی یک فرآیند علمی است که نیاز به هنر و قضاوت دارد. در این مقاله آموختیم که:
به یاد داشته باشید که بهینهسازی روی دادههای گذشته انجام میشود، اما شما در آینده معامله میکنید. همیشه:
هدف نهایی ساخت سیستمهایی است که در بلندمدت پایدار باشند، نه کسب سودهای کلان در کوتاهمدت.
امیدواریم این راهنمای جامع به شما در ساخت استراتژیهای معاملاتی قویتر و مطمئنتر کمک کرده باشد. کدهای ارائه شده را اجرا کنید، پارامترها را تغییر دهید و با ایدههای خود آزمایش کنید. اگر مایل هستید روش تعریف استراتژی معاملاتی را در پلتفرم تریدبرد بیاموزید پیشنهاد می کنیم فیلم آموزشی تهیه شده در این رابطه را با عنوان تعریف استراتژی معاملاتی در پلتفُرم تِریدبُرد مشاهده کنید . موفق و پرسود باشید! 🚀